“The President, Vice President and all civil Officers of the United States, shall be removed from Office on Impeachment for, and Conviction of, Treason, Bribery, or other high Crimes and Misdemeanors.” Article II, Section 4, US Constitution
Professor Anat Rafaeli and I teach a course at the Technion which is intended to teach students with a background in psychology the tools of Data Science and specifically how to answer research questions from the social sciences with internet data. As part of the course, students chose a research question and answer it during the semester, using the tools we teach them.
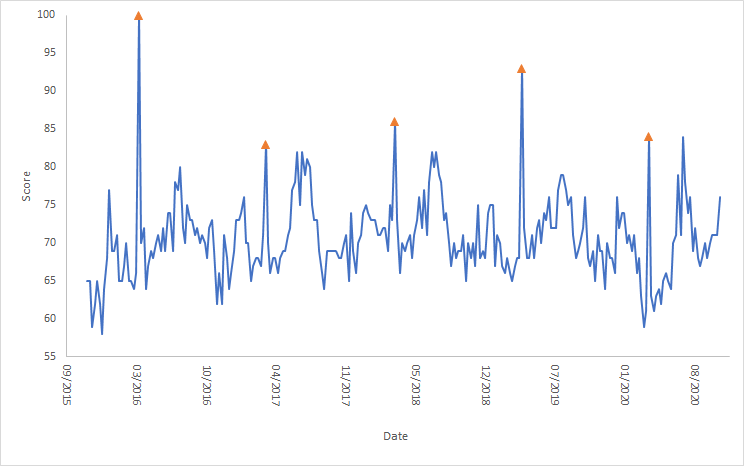
A couple of years ago, while explaining their research question, one of the students (whose name I don’t have anymore, but will be happy to add him, if he’s reading this) showed us an intriguing chart: It displayed the search volume (from Google Trends) for the term “impeachment” for the period of a few months before and after President Trump was inaugurated. There were several spikes during that year from people searching for how to impeach the president. I didn’t find this particularly surprising given the news coming from the US.
What was surprising was a similar chart he showed us for the same period around President Obama’s inauguration. It showed similar spikes! I hadn’t heard of anyone who wanted to impeach Obama, so that spike was shocking to me.
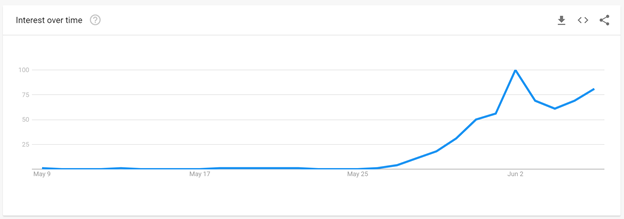
Recently I repeated the exercise this time adding data from similar time periods around President Biden’s inauguration (Technical note: For the first two presidents I used the “impeachment” topic, while for Biden I used the term “impeach Biden”, to exclude searches related to Trump’s impeachment trial). You can see the results in the figure below.

As you can see, each president has people searching for how to impeach them, first around the time that they are elected and then around inauguration. After these two events “impeachment” spikes every so often (as you can see in the Obama and Trump spikes at the end of May). More broadly, here’s Obama’s entire second term:
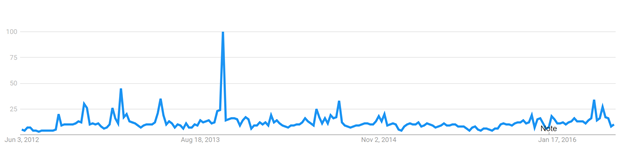
Who are these people, who are so eager to impeach their president?
We can try to answer this question by looking at the correlation between how each state voted in the recent Presidential elections and the percentage of people searching for impeachment of a president. The graphs below plot the percentage of people in each state who voted for Biden as president (i.e., roughly speaking, are Democrats) compared to the search volume for impeachment.
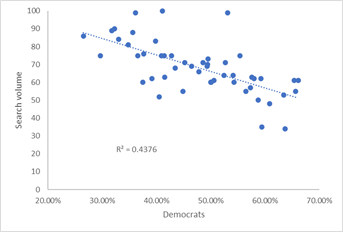
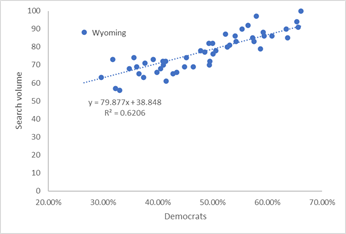
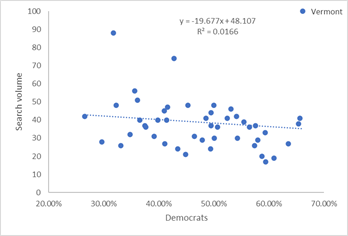
People who wanted to impeach Obama where mostly from republican states, as shown by the negative correlation between search volume and the percentage of Democrats in the state. The opposite is true for people who search for impeachment during Trump’s first months in office. With Biden the correlation is much worse, but the data is skewed by a single point when, if removed, is again reasonable (R2=0.13): For some reason, the mostly Democratic voters in Vermont are those searching more often for Biden’s impeachment.
What’s the bottom line? If you don’t know anyone who thinks your favorite president should be impeached, you just don’t know the right people.