“It is a sobering thought that when Mozart was my age, he had been dead for two years.” Tom Lehrer
If you look back at the papers you’ve published over the past year and you think you had a good year, think again. According to DBLP, 5 authors published more than one paper every day of last year (that’s more than 365 papers), and 361 authors published over 100 papers a year. I know many scientists who read fewer than 100 papers per year.
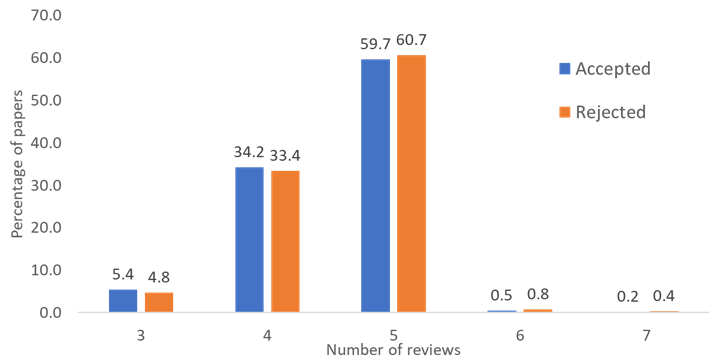
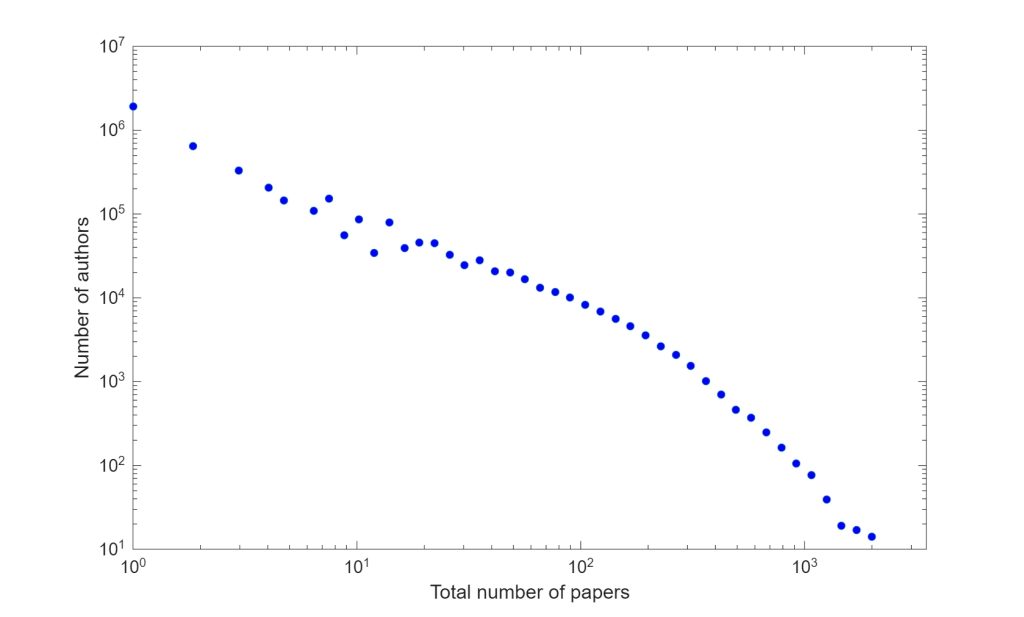
The figure below shows the distribution of the number of papers per author for all of DBLP, while the second figure shows the number of papers in AI venues, broadly defined (ICML, NeurIPS, KDD, WWW, etc.).
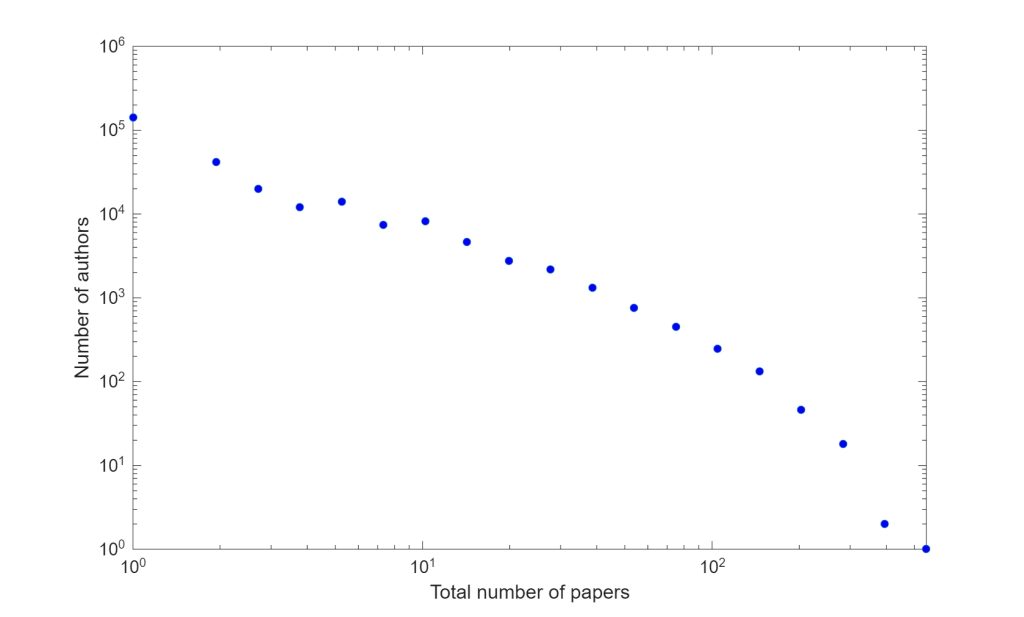
Who are these prolific authors? Among the top 50, there are 20 from China and another 6 from Hong Kong, 13 from the USA, 7 Singaporeans, two Australians and 2 from the EU.
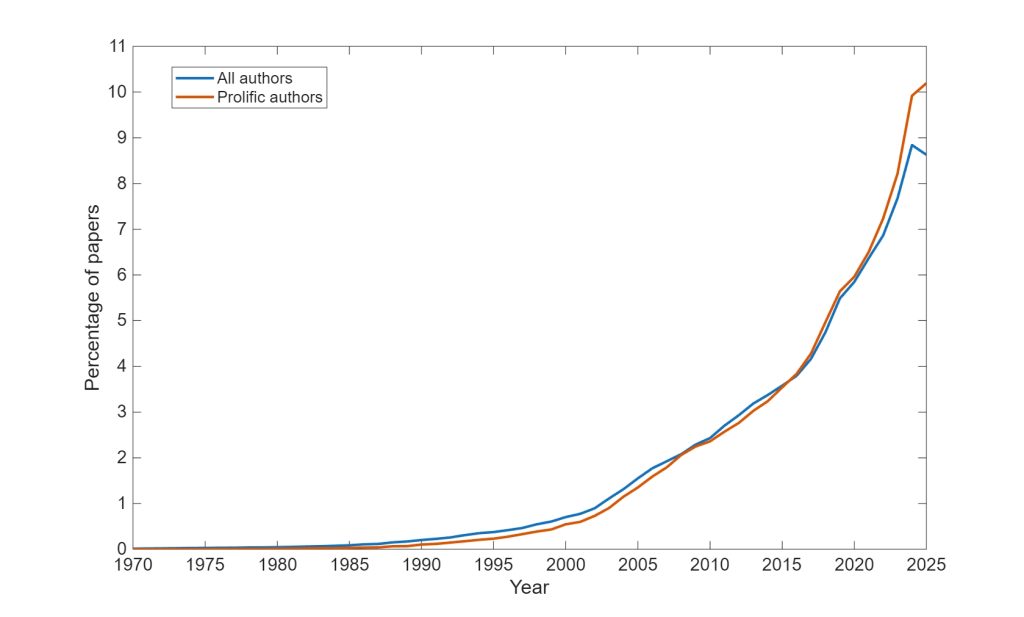
If we define prolific authors as those who have published over 500 papers during their career, we can plot the percentage of their papers over the years, compared to the same for all other (less “productive”) authors. As the figure below shows, for most of the time since 1970 the two groups have looked similar. Then, since around 2020, they’ve began to diverge, and the prolific authors begin to publish much more than the rest of us.
Another hint about these authors comes from looking at those who publish most each year, and their tenure at the time. Tenure, in this context, is the number of years since they’ve started publishing. If the population of scientists was constant, we’d expect this tenure to be the same, but my data is finite and there are more and more scientists, so the slope of the tenure is lower. The figure below shows the data for the 100 most prolific authors each year. Over most years the slope of the tenure is around 0.3 (as you can see from the dotted line, which was fit to data up to 2015). Then, around 2018 it diverges, and the tenure rapidly increases.
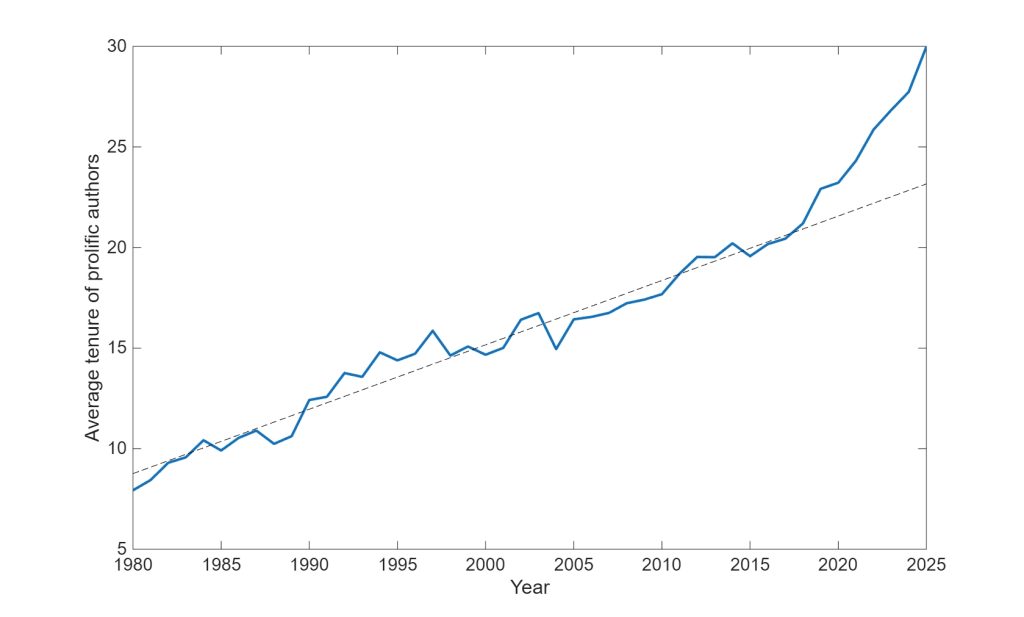
My understanding, therefore, is that in the past 8 years or so, senior people have began adding their names to publications in ways that they wouldn’t have before then. This is especially true in countries that reward publications (either with academic accolades or financial rewards).
But this brings me to an interesting fact. According to the widely-adopted recommendations of the International Committee of Medical Journal Editors (ICMJE), “authorship be based on the following 4 criteria:
- Substantial contributions to the conception or design of the work; or the acquisition, analysis, or interpretation of data for the work; AND
- Drafting the work or reviewing it critically for important intellectual content; AND
- Final approval of the version to be published; AND
- Agreement to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.“
And all 4 criteria must be met. That means, for example, that being the head of a lab who brought the money to conduct the work is not sufficient to claim authorship. She must also be able to vouch for the accuracy and integrity of the work and to approve its final version.
I strongly doubt that someone who has published more than one paper every day of the year can, in good conscience, apply all four criteria to each of the papers.
Why does it matter?
First, like it or not, publication counts are used as a signal to decide on academic merit and in some cases on financial reward. Otherwise, why would these people put their names on so many papers? Thus, ignoring the assumption that having one’s name on a paper means that they’ve been involved in the work causes that signal to be meaningless.
Second, as noted above, it can be considered unethical or fraudulent, at least according to ICMJE.
How can we solve this problem?
I don’t think there’s one way to do it. Some conferences (e.g., IJCAI 2026) have begun asking authors to pay per submission if the authors submit more than one paper to the conference. This is good but it isn’t going to change much for those who are in rich universities or labs.
Another way that’s widely used is authorship statements, though these are easily abused.
Perhaps large publishers should cap the number of papers that an author can submit to them. If the ACM, for example, would not allow more than, e.g., 24 papers per author per year (2 papers a month sounds like a good number to me), then authors will have to choose which papers they really worked on. However, perhaps they’ll just put their names on the papers they think will have the most impact.
What do you think? Do you have good solutions?